How RAG Pipelines Work: A Practical Guide for Building Context-Aware AI Applications

Let’s explain it this way: a customer service manager at a fast-growing SaaS company decides to deploy an AI chatbot to handle support tickets. The model is sharp, trained on billions of tokens, fluent in every technical topic imaginable. On Day 1, it impresses everyone. By Day 3, it starts confidently citing a return policy that was updated 6 months ago. By week two, it’s referencing a product feature that no longer exists. By month one, the support team is manually correcting AI responses more than they’re actually saving time.
This is a story playing out across thousands of companies right now.
The technology built to break that seal is called Retrieval-Augmented Generation, and the architectural pattern that powers it is the RAG pipeline.
This blog is for developers, product teams, and anyone working with an ai app development company in usa who wants to understand not just what RAG is, but how to actually build one that works, at the level of architecture decisions that determine whether your AI application becomes a competitive advantage or a liability.
What Is AI RAG?
So, what exactly is AI RAG?
RAG (Retrieval-Augmented Generation) is a technique that extends an LLM’s knowledge beyond its training data by dynamically pulling relevant information from an external source at query time. Rather than relying on the model “already knowing” the answer, a RAG system retrieves supporting documents and feeds them to the model as context before generating a response.
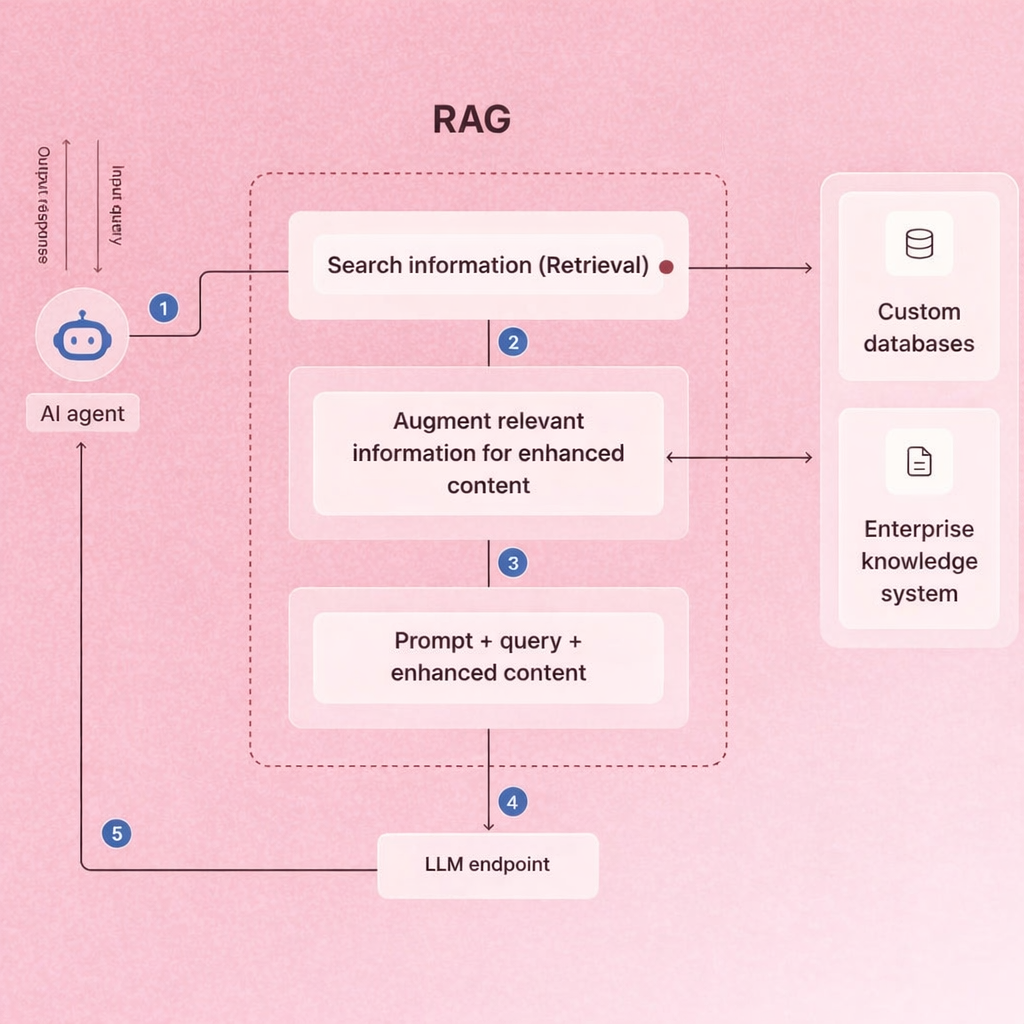
Think of it this way: instead of asking a doctor to answer from memory alone, you hand them the patient’s full medical file first. The result is more accurate, grounded, and trustworthy, which is exactly what enterprise AI applications need.
This approach is central to augmented ai the broader design philosophy of making AI systems more reliable by supplementing model knowledge with external, verifiable data sources. To understand the different AI model types that power these systems, our detailed article on Types of Generative AI is a useful starting point.
Why RAG Is Important For AI Applications
Businesses that deploy AI-powered products face a consistent challenge: generic AI models don’t know their domain. A legal tech company can’t rely on an LLM trained on general web data to accurately answer questions about their case files. A healthcare platform can’t serve patients with responses based on training data from years ago.
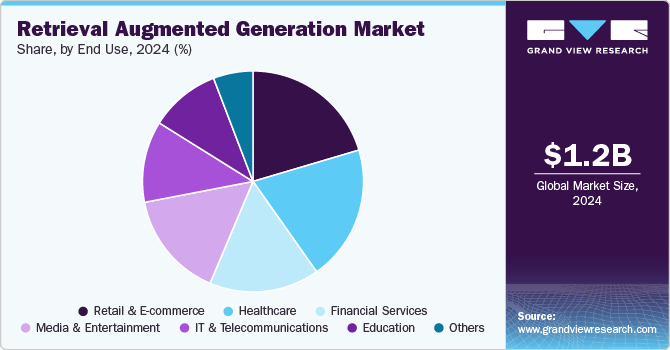
The numbers reflect just how fast this technology is being adopted. According to Grand View Research, the global RAG market was valued at USD 1.2 billion in 2024 and is projected to reach USD 11.0 billion by 2030, growing at a compound annual rate of 49.1%. On the research side, academic interest has exploded in parallel. A 2025 systematic review on arXiv noted that over 1,200 RAG-related papers were published in 2024 alone, compared to fewer than 100 the year before. That pace of growth signals a technology quickly crossing from experimental to production-grade.
This is where purpose-built RAG systems, often developed by an experienced ai powered mobile app development company or an ai chatbot app development company deliver measurable value. RAG-powered products can:
- Answer questions grounded in proprietary documents
- Surface up-to-date product information without model retraining
- Handle domain-specific terminology with precision
- Avoid hallucinations by anchoring responses to retrieved source material
Understanding the RAG Architecture
To build a reliable RAG system, you need to understand its architecture end-to-end. A well-designed rag architecture diagram typically shows two primary workflows: the indexing phase and the query phase.
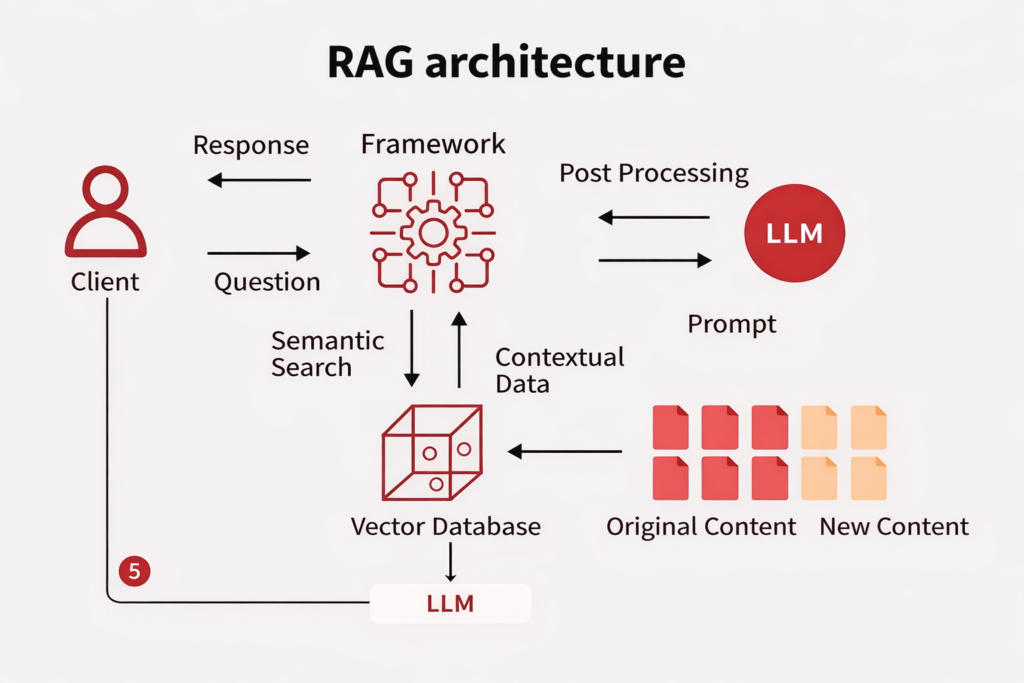
Phase 1: Indexing (Making Your Data Retrievable)
This phase runs offline and prepares your data for future retrieval.
- Data Ingestion
The pipeline begins by connecting to data sources: PDFs, internal wikis, CRM exports, support tickets, product documentation, or any structured and unstructured content. Diverse source handling is critical here; real enterprise environments rarely have data in a single clean format. - Extraction and Cleaning
Raw source content is extracted and stripped of noise. For PDFs, this might involve libraries that parse layout structure. For web pages, HTML tags are cleaned away. The goal is retrievable, readable text with metadata preserved, such as document title, author, creation date, and section headers. - The Chunking Approach
Extracted documents are rarely small enough to embed and retrieve wholesale. The Chunking Approach, breaking documents into smaller segments, is one of the most consequential decisions in any RAG pipeline. Poor chunking leads to poor retrieval, no matter how strong everything else is.
There are several chunking strategies worth knowing:
- Fixed-Length Chunking: Splitting text at every N tokens. Simple to implement, but often cuts sentences mid-thought, fragmenting meaning.
- Semantic Chunking: Splitting based on natural topic shifts, section breaks, or paragraph boundaries. Produces chunks that preserve coherent meaning.
- Recursive Chunking: Creating a hierarchy of chunks, coarse parent chunks containing finer child chunks, enabling retrieval at multiple levels of granularity.
- Proposition-Based Chunking: Breaking content into individual factual claims or statements. Particularly effective for factual Q&A use cases where precision matters.
- Agentic Chunking: Deploying an LLM to intelligently decide where to split documents based on content structure and information density. Best suited for documents with unpredictable formatting.
For most production applications, semantic or recursive chunking outperforms simple fixed-length splits. Chunk size typically falls between 200 and 500 tokens, but this should be tuned against your specific retrieval benchmarks.
- Embedding Generation
Each chunk is converted into a numerical vector: a high-dimensional representation of its semantic meaning using an embedding model. Common choices include OpenAI’s embedding models, Cohere’s Embed API, and open-source options from Hugging Face. Domain-specific embedding models (trained on legal, medical, or financial corpora) often outperform general-purpose models in specialized applications. - Vector Storage
Embedded chunks are stored in a vector database such as Pinecone, Weaviate, Qdrant, or Chroma. These databases are built for fast similarity search, finding vectors that are semantically close to a query vector across potentially millions of stored chunks.
Phase 2: The Query Pipeline (Answering in Real Time)
When a user submits a question, the query pipeline kicks in:
- Query Embedding
The user’s question is embedded using the same model used during indexing, placing it in the same vector space as the stored chunks. - Retrieval
The system searches the vector database for chunks whose embeddings are most similar to the query embedding. The default approach uses cosine similarity, but more advanced setups employ hybrid search. Combining vector-based semantic similarity with keyword-based scoring (like BM25). Hybrid search consistently outperforms either method alone, especially for queries where exact terminology matters. - Reranking
An optional but highly valuable step: the initially retrieved candidates are re-scored by a more computationally intensive model (a cross-encoder or a dedicated reranker). This second-pass filtering pushes the most genuinely relevant chunks to the top, improving the quality of context passed to the LLM. - Augmentation
Retrieved chunks are formatted and inserted into the prompt alongside the user’s original question. This step, where retrieval meets generation, is what earns the “augmented” in augmented ai. Prompt design matters here: the model needs clear instructions on how to use the provided context. - Generation
The LLM, whether GPT-4, Claude, LLaMA, or another model, receives the augmented prompt and generates a response grounded in the retrieved content. Because the model has access to relevant source material, responses are more accurate and less prone to hallucination.
The RAG Agent: Taking RAG Beyond Simple Retrieval
A standard RAG pipeline retrieves once and generates once. But complex real-world queries often require more than that. This is where the rag agent pattern emerges.
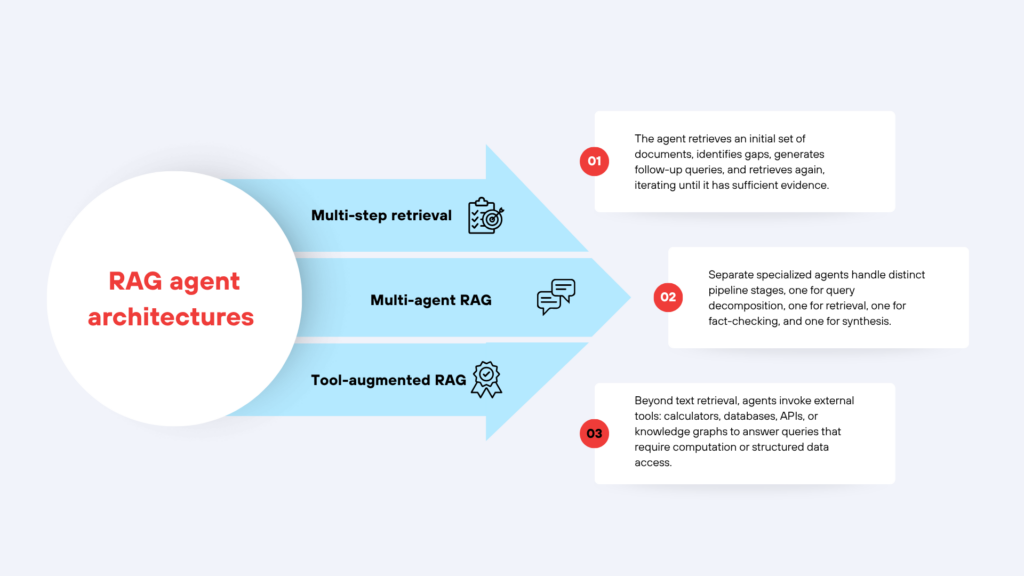
A RAG agent uses an LLM not just for final generation, but as an active decision-maker throughout the pipeline. Common RAG agent architectures include:
- Multi-step retrieval: The agent retrieves an initial set of documents, identifies gaps, generates follow-up queries, and retrieves again, iterating until it has sufficient evidence.
- Multi-agent RAG: Separate specialized agents handle distinct pipeline stages, one for query decomposition, one for retrieval, one for fact-checking, and one for synthesis.
- Tool-augmented RAG: Beyond text retrieval, agents invoke external tools: calculators, databases, APIs, or knowledge graphs to answer queries that require computation or structured data access.
RAG agents are particularly well-suited for enterprise applications where questions span multiple documents, require multi-hop reasoning, or need information synthesized from heterogeneous data sources. Building these systems requires careful orchestration; frameworks like LangGraph and LlamaIndex provide the infrastructure to do so reliably.
Advanced Techniques That Improve RAG Quality
Building a working RAG pipeline is a starting point. Building a high-performing one requires attention to the following:
Query Transformation
User queries are often ambiguous or incomplete. Before retrieval, apply transformations like:
- HyDE (Hypothetical Document Embeddings): Generate a hypothetical ideal answer, then retrieve documents similar to that hypothetical, often outperforming direct query retrieval.
- Multi-query generation: Rephrase the original query in several ways and aggregate results from all versions.
- Sub-query decomposition: Break complex questions into smaller, targeted sub-questions.
Context Distillation
LLMs have limited context windows. If you retrieve too many chunks, the model may struggle to process them effectively. Techniques like extractive summarization or semantic compression can trim retrieved content to only what’s essential, reducing noise and improving generation quality.
Evaluation Metrics
Measuring RAG performance requires tracking multiple dimensions:
- Context Precision: What proportion of retrieved content actually contributed to the final answer?
- Context Recall: Did the retrieval step surface everything the model needed?
- Faithfulness: Is the generated answer grounded in the retrieved context, or did the model introduce unsupported claims?
- Answer Relevance: Does the response actually address what the user asked?
Frameworks like RAGAS provide standardized evaluation pipelines covering all four dimensions, making it easier to identify which part of your RAG system needs improvement.
Choosing Tools and Implementation Path
Modern RAG development benefits from a mature ecosystem. LangChain and LlamaIndex are the most widely adopted frameworks for building modular RAG pipelines. Haystack offers a production-focused alternative with built-in observability. For vector storage, Pinecone is the leading managed option, while Qdrant and Chroma are strong open-source alternatives.
Any ai app development company in usa working on production RAG deployments will typically combine these tools with monitoring infrastructure: logging queries, retrieval results, and user feedback to enable continuous improvement post-launch. If you’re exploring how to embed RAG into a broader SaaS product, our guide on How to Build AI-Powered SaaS Applications walks through the full architectural picture, including multi-tenant isolation and inference cost management.
Conclusion
RAG represents a fundamental shift in how AI systems are designed for real-world deployment. By connecting LLMs to external knowledge sources through a structured retrieval pipeline, organizations can build AI products that are accurate, current, and domain-aware without retraining massive models from scratch.
The core principles: thoughtful chunking, high-quality embeddings, hybrid retrieval, structured augmentation, and continuous evaluation apply whether you’re building a customer-facing chatbot, an internal knowledge assistant, or a complex multi-agent reasoning system. As the AI ecosystem matures, RAG will only grow more sophisticated, incorporating multimodal retrieval, self-improving feedback loops, and deeper agentic orchestration.
For any team, whether an ai chatbot app development company, an enterprise IT department, or an independent development team, mastering the RAG pipeline is one of the highest-leverage investments you can make in AI capability today.
To know more, share your questions with info@techexactly.com


