Top 7 Data Quality Issues in Healthcare AI (and How to Fix Them)

Healthcare AI is having a moment. From predictive diagnostics to AI-assisted triage, the promise is enormous. But one truth nobody likes to say out loud: data quality issues in healthcare are silently undermining these systems every single day. You can have the most sophisticated model in the world… feed it inconsistent, incomplete, or improperly governed data, and the outputs will be wrong. Sometimes dangerously wrong.
If I may explain with an example: say you are handing a brilliant surgeon a patient file where half the pages are missing, some are from a different patient, and the lab results are three days old. Would you trust the diagnosis? That’s exactly what we’re asking healthcare AI to do every single day.
80% of healthcare data is unstructured, from clinical notes and imaging reports to discharge summaries, making it one of the hardest industries in the world to achieve reliable AI training pipelines. (Source)
At Tech Exactly, we’ve worked with healthcare organizations across the US and UK, building AI-powered apps that have to meet the highest clinical and compliance standards. These seven issues are the ones we see almost universally, and each one has a fix.
Before we dive in, it’s worth clarifying what is data integrity in healthcare. Simply put, it’s the assurance that health data is accurate, complete, consistent, and trustworthy throughout its entire lifecycle from the moment a nurse enters a patient’s vitals to the second an AI model reads them to generate a risk score. When that integrity is compromised anywhere along the line, the consequences cascade.
The 7 Critical Data Quality Issues (and Their Fixes)
We’ve seen the following quality issue patterns across startups and enterprise health systems alike in the US, in the UK, across EHR platforms, mobile apps, and AI diagnostics tools. The problems change in scale, rarely in nature.
1. Incomplete and Missing Patient Records

A patient with a complex history of comorbidities walks into an emergency department. The AI-powered triage tool assesses them, but it’s working with a chart that’s missing two years of medication history because they switched providers.
Missing data is arguably the most pervasive of all data quality issues in healthcare. It happens for reasons both human (clinicians in a rush, non-standardized intake forms) and systemic (siloed EHR platforms that don’t talk to each other).
The Problem:
- Missing lab values and vital history
- Incomplete medication records
- Absent prior diagnosis codes
- AI models trained on gaps produce biased predictions
The Fix:
- Implement mandatory field validation at intake
- Use HL7 FHIR APIs for cross-platform record syncing
- Deploy ML-based imputation for non-critical gaps
- Build audit dashboards that surface completeness scores
“Incomplete records don’t just hurt model accuracy; they encode systemic gaps. If your AI is trained predominantly on complete records from certain demographics, it becomes structurally biased against everyone else. You need to treat data completeness as a clinical safety issue, not a technical one.” — Manas, Mobile App Architect, Tech Exactly
2. Inconsistent Data Formats Across Systems

Date of birth formatted as MM/DD/YYYY in one system, YYYY-MM-DD in another. Blood pressure recorded as “120/80” in the EHR, “120 over 80” in a mobile app, and “systolic: 120” in a wearable export. These seem like cosmetic differences, but to a machine learning model parsing millions of such records, they’re catastrophic inconsistencies.
This is a core challenge in data quality management in healthcare, especially for organizations scaling their Healthcare Mobile App Development Services across multiple platforms and care settings.
The Problem:
- Different date, unit, and naming conventions across systems
- Non-standard ICD codes across legacy platforms
- Free-text fields with unstructured values
- Multi-source data pipelines breaking model input formatting
The Fix:
- Enforce FHIR R4 as the interoperability standard
- Build ETL pipelines with dedicated format normalization layers
- Standardize ICD-10/SNOMED CT code mappings
- Deploy NLP parsers to handle free-text standardization at ingestion
3. Duplicate and Fragmented Patient Identities

It’s more common than you’d think: a patient has one record from their primary care physician, a separate one from an urgent care visit at a different network, and a third from a hospital stay. Each contains partial, sometimes conflicting information. An AI seeing all three might treat them as three different patients or worse, merge them incorrectly and stack one patient’s allergies onto another’s record.
Enterprise Master Patient Index (EMPI) failures are a major source of what the industry calls “patient identity fragmentation”, and it’s one of the most dangerous data quality issues and solutions practitioners wrestle with in production AI systems.
The Problem:
- Duplicate MRNs across health systems
- Partial record merges create chimera patient profiles
- AI is attributing the wrong history to the wrong patient
- Downstream medication errors and misdiagnosis risk
The Fix:
- Implement probabilistic EMPI matching algorithms
- Use biometric or multi-factor patient matching at registration
- Enforce unique national patient identifiers where available
- Run de-duplication pipelines before data reaches model ingestion
“In one project we worked on, the same patient had seven duplicate records across three hospital networks. The AI was essentially running a differential on a Frankenstein patient. We spent more engineering time resolving identities than building the actual prediction model. That ratio shouldn’t exist, identity resolution must be foundational, not an afterthought.“ — Manas, Mobile App Architect, Tech Exactly
4. Training Data Bias and Underrepresentation

The story of dermatology AI models trained almost entirely on lighter skin tones is now well-documented, but it’s just the most visible example of a systemic problem. Training datasets in healthcare have historically overrepresented certain demographics: urban populations, insured patients, and specific geographies. Any AI model built on this data will perform measurably worse on underrepresented groups.
For any Healthcare App Development Company in USA building tools designed to serve diverse patient populations, addressing training bias is a clinical and ethical imperative, and increasingly a regulatory one too.
52% of AI diagnostic tools in healthcare show measurable performance gaps between the majority and minority demographic groups. (Source)
The Problem:
- Models trained on homogeneous datasets
- Worse accuracy for minority and underserved demographics
- Perpetuating existing care disparities, now at an algorithmic scale
- Growing regulatory and liability exposure in both the US and UK markets
The Fix:
- Audit training datasets for demographic coverage before use
- Implement stratified sampling and re-weighting techniques
- Use federated learning to train across geographically diverse sites
- Run equity-specific performance evaluations as part of model validation
5. Inadequate Data Governance and Access Controls

When everyone, and no one, owns the data. Poor data quality management in healthcare often is a governance problem. When there’s no clear ownership of data quality, when data stewards don’t exist, when access policies are loosely defined or inconsistently applied, quality degrades naturally over time. People edit records without audit trails. Sensitive data gets copied into unsecured environments for testing. The AI pipeline ingests whatever it can reach.
This becomes a HIPAA problem very quickly. As a Healthcare App Development Company in UK and US markets, Tech Exactly builds governance frameworks into healthcare apps from day one because retrofitting governance onto a live system is harder than building it in from the start. See our full guide on how to build a HIPAA-compliant app for the technical specifics.
The Problem:
- No defined data ownership or stewardship roles
- Overly permissive access controls across systems
- No audit trails on data modifications or PHI access
- HIPAA and GDPR non-compliance exposure
The Fix:
- Assign formal data stewards per clinical domain
- Implement role-based access control (RBAC) across all systems
- Enable immutable audit logging on all PHI access and modification
- Conduct quarterly data governance reviews with executive sign-off
>> Our Suggestion: Strong governance is also the backbone of any credible HIPAA audit process. Don’t wait for a breach to discover your gaps.
6. Real-Time Data Latency and Staleness

Say your AI early-warning system flags a patient as low risk for sepsis at 8 am based on vitals from 11 pm, the night before. Their condition deteriorated at 3 am, but that data is still sitting in a batch sync queue. The model never saw it.
Data latency is an underrated data quality issue in clinical AI, especially as healthcare moves toward real-time decision support. The question of what is data integrity in healthcare must include a temporal dimension, as data isn’t just about accuracy; it’s about relevance right now.
3–6 hours is the average EHR data sync delay in traditional batch-processing hospital systems, a window wide enough for rapid clinical deterioration to go undetected by AI monitoring tools.
The Problem:
- Batch ETL jobs with multi-hour processing delays
- AI operating on stale patient state during critical windows
- Missing acute clinical events that fall inside the gap
- Incorrect risk scores are driving wrong or delayed interventions
The Fix:
- Migrate to event-driven architecture using Kafka or Kinesis
- Implement streaming FHIR subscriptions for real-time data push
- Build data freshness monitoring dashboards with alerting
- Define SLAs on maximum tolerable data age per clinical use case
7. Inadequate De-identification and Privacy Controls
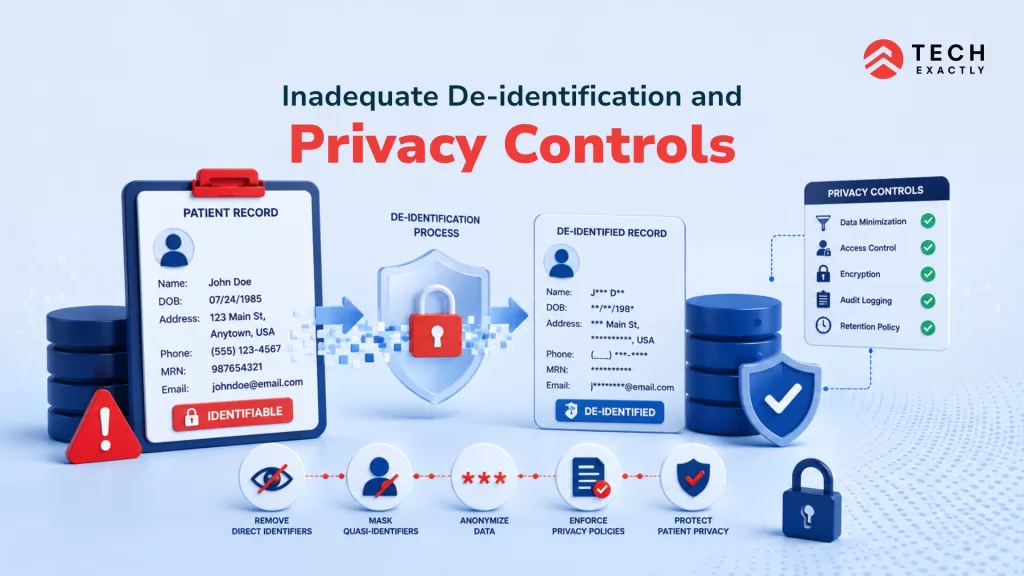
This is the issue that keeps healthcare CISOs up at night. Using inadequately de-identified patient data to train AI models is potentially a federal violation. Yet it happens with surprising frequency, often not through malice but through a genuine misunderstanding of what “de-identified” actually requires under HIPAA’s Safe Harbor or Expert Determination standards.
Re-identification risk is real. Research has shown that in some datasets, as few as three or four data points: ZIP code, date of birth, and gender are enough to uniquely re-identify individuals. Every Healthcare App Development Company in USA or UK building AI tools must treat de-identification as a rigorous technical process. We cover this in depth in our resource on managing patient data in AI systems.
The Problem:
- Shallow anonymization that remains re-identifiable
- Synthetic data not validated for re-identification safety
- PHI leaking into AI training and development environments
- Non-compliance with the HIPAA Safe Harbor’s 18 required identifiers
The Fix:
- Apply the HIPAA Expert Determination methodology for complex datasets
- Use differential privacy techniques during model training
- Validate synthetic data using re-identification risk scoring tools
- Enforce data use agreements and the minimum necessary rule strictly
For a comprehensive technical checklist, see our guide on how to secure healthcare apps.
The Bottom Line: Data Quality Is a Patient Safety Issue
Every one of the issues above has a direct line to patient outcomes. A model trained on incomplete data will miss diagnoses. A model fed stale vitals will generate wrong risk scores. A system with poor identity resolution might mix up patients. In any other engineering domain, these would be bugs. In healthcare AI, there are patient safety risks.
The good news is that none of these problems is unsolvable. They require investment: in infrastructure, in governance, in engineering rigor, but they’re all fixable. The teams that solve them build AI systems that actually earn clinical trust.
Whether you’re partnering with a Healthcare App Development Company in USA, working with Healthcare Mobile App Development Services in the UK, or building in-house, the quality of your data pipeline will define the ceiling of what your AI can ever achieve. Build the foundation right. To know more, share your questions with info@techexactly.com